



聊起服务器,大家首先想到的就是“三大件”,即CPU, 内存,硬盘,但是作为服务器不可或缺的部件,网卡也应该占据一席之地,网卡的功能主要有两个:
一是将服务器的数据封装为帧,并通过网线将数据发送到网络上去;
二是接收网络上其它设备传过来的帧,并将帧重新组合成数据,发送到所在的服务器中。
网卡最主要的参数是速率带宽,代表着服务器网络的整体处理能力。云计算,大数据处理,高速存储的需求推动了网络带宽的发展,云上客户对网络速度及网络带宽的关注度不断提升。业务对数据中心的流量产生巨大的冲击,企业需要大量,大带宽的服务器组成集群系统,协同完成工作。网卡从1G到10G普及用了十年时间,到现在很多IDC机房用的还是千兆网络,但是从10G到25G成加速普及的趋势,只用了不到3年时间,互联网头部公司已经基本切换到25G网络,并且已经开始部署50G和100G。
随着网卡速率越来越高,业务对延时的要求越来越低,传统的x86服务器已经不能满足业务的需求,于是出现了如DPDK这种软件的解决方案,采用轮训方式和在用户态实现数据包处理,可以明显提高服务器网络性能。DPDK好处就是投入少,收益大,传统网卡加上软件套件就可以实现性能提升,缺点在于需要专门划出一部分CPU核来处理数据包。但是随着VXLAN等overlay协议以及OpenFlow、Open vSwitch(OVS)等虚拟交换技术的引入,使得基于服务器的网络数据平面的复杂性急剧增加,传统网卡固定功能的流量处理功能无法适应SDN和NFV ,而且网络接口带宽的增加意味着在软件中执行这些功能会占用大量的CPU资源, 和当前云计算的理念背道而驰,于是智能网卡的概念应运而生。
不同于传统网卡,智能网卡同时具备高性能及可编程的能力,既能处理高速的网络数据流,又能对网卡进行编程,实现定制化的处理逻辑
智能网卡的三种形式
目前,智能网卡设计采用以下三种形式之一:
- 多核智能网卡,基于包含多个CPU内核的ASIC
- 基于现场可编程门阵列(FPGA)的智能网卡
- SOC,即片上系统,它将硬件可编程FPGA与ASIC网络控制器相结合
不同的实现方式在成本、可编程性和灵活性方面各有优劣,ASIC具有价格优势,但灵活性有限,尽管基于ASIC的NIC相对容易配置,但最终功能将受到基于ASIC中定义的功能的限制,某些较复杂的负载可能无法得到支持, 相比之下,FPGA NIC是高度可编程的,并且可以相对有效地支持几乎任何功能,不过FPGA问题是编程难度大且价格昂贵,对一些小客户不太友好,针对更复杂的用例,SOC是较佳的SmartNIC选择,价格与性能兼具、易于编程且高度灵活。
具体说来,智能网卡为数据中心网络提供了几项重要优势,包括:
1.通过直接在网络接口卡上执行任务来加速网络、存储和计算任务,消除了在服务器上运行这些工作负载的需要,并释放了CPU周期,从而显着提高服务器性能并降低总体功耗,进而降低总体拥有成本。
2.卸载日益复杂的网络任务,包括诸如VxLAN等复杂隧道协议和OVS虚拟交换机等,使服务器处理器能够执行实际的创收性任务。
3.通过在更快速的硬件而不是较慢的软件中去执行卸载功能,从而提高有效网络带宽和吞吐量,并提供附加的、灵活的功能,以适应新的和不断变化的网络和存储协议。
其实智能网卡在大型互联网公司及头部CSP上已经开始应用,核心思想就是把业务负载卸载到专用硬件上,如微软在Azure上使用FPGA来实现CPU卸载、网络加速,而AWS甚至 发展出一套Nitro 架构来实现VPC, EBS,存储等业务的硬件卸载,国内阿里巴巴的神龙架构思想类似,其架构核心就是一块MOC卡,整个Hypervisor完完全全运行在这张卡上面,服务器的CPU和内存完全可以释放出来给客户。
H3C全新发布的UIS 7.0赤霄加速架构,是业界先进的实现前后端同时智能加速的超融合架构。以智能加速卡为核心前后端到端全程加速、主机侧损耗为零,相同核数CPU条件下,对比非加速方案,可以多创建50%以上的虚拟机,每虚拟机成本降低30%以上,IOPS性能提升10倍以上。同时拥有业界超短IO路径的无损网络,网络时延从毫秒级降低到纳秒级。可同时承载虚拟化,裸金属,容器,函数计算的全运行态。
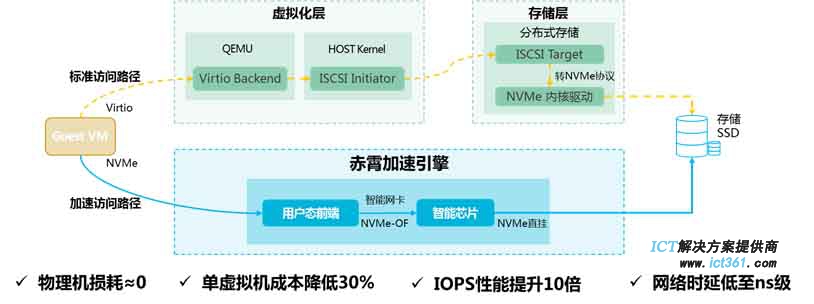
H3C 超融合架构UIS在最新7.0版本中采用了智能网卡,把存储、网络的处理完全下沉到智能加速卡上,几乎全部CPU资源都可以用于计算,大大提升了算力,相比当前超融合方案,具备更高的性能和更低的TCO总体拥有成本。
发表评论